This guide is highly recomended for students enrolled in HINF 5008 - Computational Methods in Health Informatics
The resources provided here aim to help you apply computational methods in your research, while learning more about data-mining topics and how to get help with new tools.
This guide focuses specifically on using the opensource statistical programing language R, but more on other data analytics resources can be found through the Data-Intensive Research LibGuide.
Getting a better understanding of how the following terms are used will help you as you explore these resources and learn to apply them in your research.
Data Science
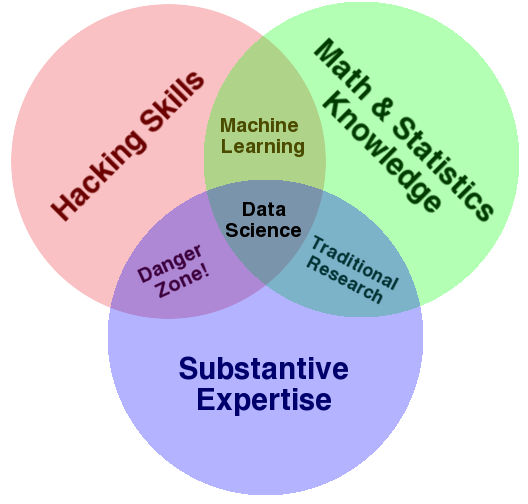
How to read the Data Science Venn Diagram:
The primary colors of data: hacking skills, math and stats knowledge, and substantive expertise
Defining Big Data
Gartner's Definition:
“Big data” is high-volume, -velocity and -variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.
6 "V"s of Big Data-- these depend on who's writing the definition, but here's an explanation of those aspects:
For more on these definitions see Neil Biehn's article in Wired and Gartner's Big Data Definition explained in Forbes
TED on Big Data
Making Sense of Too Much Data Play list of ten presentations given at conferences for the organization, Technology, Entertainment, Design (TED). These talks explore practical, ethical, and visual ways to understand near-infinite data.
Machine Learning
Sometimes integrated with "statistical learning", machine learning refers to a set of algorithmic approaches and tools for modeling and understanding complex data sets (James, 2013). Machine learning "investigates how computers can learn (or improve their performance) based on data. A main research area is for computer programs to automatically learn to recognize complex patterns and make intelligent decisions based on data" (Han, 2012).
Subtypes:
Data Mining
Data mining is an interdisciplinary subject that can be defined in many ways, but has also been referred to as "knowledge mining from data" or Knowledge Discovery from Data (KDD) implying that data mining is an essential step in the process of knowledge discovery and the data life cycle.
More specifically, data mining is a sub-field of computer science that integrates aspects of statistics, machine learning, database systems and data warehouses, along with information retreival in order to leverage the power of various pattern recognition techniques. Typically, data mining tries to either discover or generate preliminary insights into area's where there is little current knowledge available from large datasets.
The data mining process involves data cleaning, integration, selection, transformation, pattern discovery, pattern evaluation, and knowledge presentation.
Explore these guides for even more help and resources
